Entraîner un modèle…#
Il y a plusieurs approches. Nous allons en présenter deux: w2v et glove.
Word2Vector#
Continous bag of words (CBOW): utiliser le contexte comme input pour prévoir le mot cible.
Skip-gram: utiliser un mot comme input pour prévoir le contexte. Article original
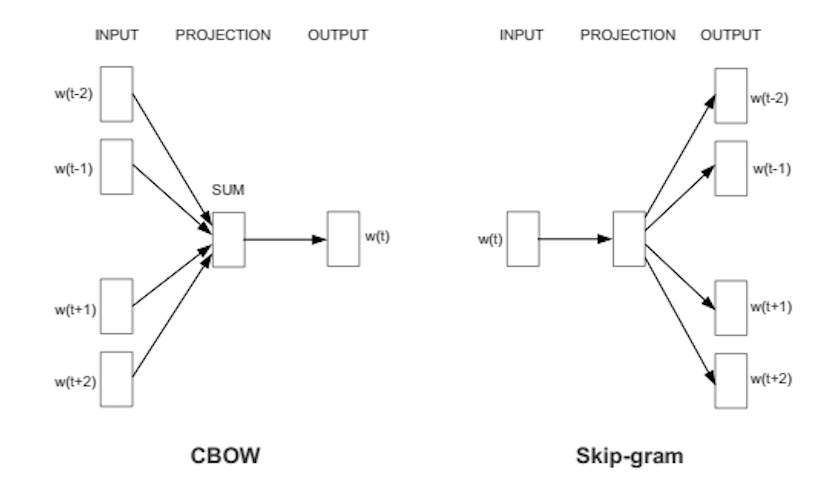
Skip-gram#
One hot encoding: un vecteur du même nombre des dimension que la taille du vocabulaire.
une couche cachée
un output (une série d’autres one hot encodings)
Le but est d’ajuster les poids pour ensuite pouvoir représenter le mot avec la cocuhe cachée. Donc la tâche qu,on donne au réseau ne sert pas à entraîner un modèle capable ensuite de réaliser cette tâche (deviner les mots du contexte), mais cela servira simplement à représenter le mot.
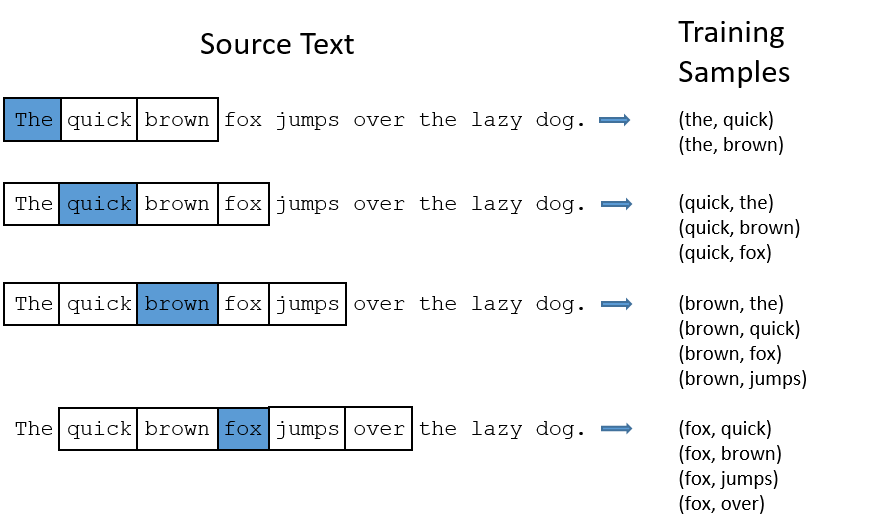
Concrètement une ligne de la couche cachée sera notre vecteur:
http://mccormickml.com/assets/word2vec/matrix_mult_w_one_hot.png
{kind=link}
L’idée est que si deux mots se trouvent statistiquemnt dans des contextes très similaires ils doivent être proches.
from gensim.models import Word2Vec
with open('fichiers/recherche.txt', 'r') as file:
recherche = file.read()
recherche = recherche.replace('\xa0', '')
recherche = recherche.replace('\n', ' ')
sentences = [s for s in recherche.split('.')]
sentences = [s.split(' ') for s in sentences]
model = Word2Vec(sentences=sentences)
model.wv.index_to_key
['de',
'',
'la',
'à',
'que',
'et',
'le',
'les',
'qui',
'ne',
'pas',
'un',
'en',
'je',
'des',
'une',
'dans',
'pour',
'ce',
'plus',
'il',
'du',
'comme',
'me',
'avait',
'par',
'elle',
'se',
'lui',
'nous',
'si',
'avec',
'qu’il',
'au',
'était',
'son',
'mais',
'sa',
'vous',
'tout',
'où',
'sur',
'—',
'même',
'qu’elle',
'cette',
'd’un',
'ou',
'est',
'ces',
'bien',
'on',
'M^(me)',
'a',
'Mais',
'ma',
'sans',
'mon',
'ses',
'd’une',
'faire',
'leur',
'M',
'quand',
'qu’on',
'Je',
'fait',
'c’est',
'y',
'Et',
'dont',
'été',
'chez',
'Il',
'moi',
'dit',
'aux',
'peu',
'aussi',
'être',
'»',
'encore',
'j’avais',
'cela',
'moins',
'quelque',
'c’était',
'fois',
'parce',
'jamais',
'avoir',
'voir',
'Swann',
'sont',
'mes',
'dire',
'n’était',
'temps',
'vie',
'eût',
'tous',
'n’est',
'car',
'peut-être',
'faisait',
'deux',
'étaient',
'très',
'ils',
'Guermantes',
'non',
'notre',
'rien',
'qui,',
'que,',
'femme',
'qu’ils',
'moment',
'toujours',
'autre',
'seulement',
'Elle',
'devant',
'pu',
'tant',
'trop',
'chose',
'jour',
'n’avait',
'gens',
'pas,',
'toute',
'moi,',
'avaient',
'toutes',
'monde',
'après',
'eu',
'pouvait',
'celui',
'l’air',
'celle',
'peut',
'yeux',
'depuis',
'La',
'déjà',
'jeune',
'entre',
'n’y',
'leurs',
'Albertine',
'personne',
'Le',
'grand',
'quelques',
'avant',
'm’avait',
'sous',
'nom',
'plaisir',
'd’être',
'Charlus',
'assez',
'laquelle',
'qu’un',
's’il',
'elles',
'homme',
'pendant',
'C’est',
'aurait',
'cet',
'ceux',
'beaucoup',
'petit',
'presque',
'qu’à',
'ainsi',
'vers',
'semblait',
'lui,',
'souvent',
'Verdurin',
'Guermantes,',
'fut',
'fût',
'serait',
'Ce',
'j’étais',
'princesse',
'duchesse',
'cause',
'maintenant',
'soit',
'doute',
'autres',
'grande',
'chaque',
'et,',
'choses',
'qu’une',
'pourtant',
'Saint-Loup',
'côté',
'alors',
'sorte',
'On',
'là',
'disait',
'ont',
'elle,',
'tu',
'petite',
'ayant',
'première',
's’était',
'Françoise',
'jours',
'j’ai',
'grand’mère',
'parler',
'seul',
'venait',
'jusqu’à',
'nos',
'donner',
'aller',
'suis',
'Gilberte',
'vu',
'fille',
'En',
'À',
'mal',
'prendre',
'Les',
'votre',
'devait',
'contre',
'seule',
'mère',
'allait',
'venir',
'n’a',
'air',
'd’autres',
'longtemps',
'n’en',
'désir',
'ni',
'point',
'qu’elles',
'près',
'lequel',
'l’autre',
'duc',
'fort',
'vue',
'peine',
'voulu',
'premier',
'femmes',
'père',
'reste',
'passer',
'besoin',
'savoir',
'd’avoir',
'faut',
'loin',
'n’avais',
'lieu',
'mieux',
'puis',
'eux',
'personnes',
'l’avait',
'trouver',
'd’ailleurs',
'milieu',
'cœur',
'chambre',
'beau',
'Vous',
'partie',
'sais',
'visage',
'Swann,',
'soir',
'façon',
'j’aurais',
'croire',
'savait',
'jeunes',
'place',
'coup',
'Si',
'qu’en',
'dès',
'mort',
'pouvoir',
'dîner',
'quelqu’un',
'celles',
'maison',
'souvenir',
'demander',
'certains',
'tel',
'telle',
'Bloch',
'surtout',
'voulait',
'instant',
'pris',
'mot',
'donnait',
'ça',
'ton',
'reste,',
'dû',
'regard',
'hommes',
'Balbec',
'plutôt',
'heures',
'trouvait',
'Comme',
'bon',
'malgré',
's’en',
'«Je',
'prince',
'auprès',
'passé',
'plus,',
'raison',
'bonne',
'vie,',
'penser',
'Car',
'fit',
'puisque',
'répondit',
'Pour',
'De',
'contraire',
'rendre',
'vrai',
'mettre',
'Odette',
'fond',
'compte',
'voix',
'tête',
'monde,',
'Un',
'part',
'amour',
'Quand',
'certaines',
'Paris',
'connaître',
'laisser',
'bien,',
'sens',
'dame',
'aucune',
'tante',
'avons',
'trois',
'genre',
'Robert',
'enfin',
'entendu',
'corps',
'Verdurin,',
'autant',
'mots',
'd’elle',
'même,',
'chercher',
'crois',
'effet,',
'l’idée',
'cru',
'aucun',
'réalité',
'Balbec,',
'tandis',
'Cambremer',
'Charlus,',
'famille',
'porte',
'Villeparisis',
'main',
'plusieurs',
'faisant',
'amis',
'l’heure',
'va',
'grands',
'pourrait',
'nouveau',
'sourire',
'lettre',
'pouvais',
'd’aller',
'lui-même',
'salon',
'paroles',
'certain',
'croyait',
'avais',
'n’eût',
'cela,',
'Nous',
'pensée',
'avez',
'n’étaient',
'ami',
'cas',
'Albertine,',
'train',
'C’était',
'd’abord',
'l’on',
'figure',
'd’Albertine',
'rester',
'force',
'nouvelle',
'effet',
'donné',
'M^(lle)',
'femme,',
'Sans',
'quoi',
'sait',
'l’un',
'nous,',
'tard',
'Ah!',
'vieux',
'te',
'autour',
'sera',
'mêmes',
'goût',
'suite',
'Dans',
'peur',
'grâce',
'étant',
'Au',
'tenait',
'connaissait',
'fin',
'savais',
'selon',
'faisaient',
'trouve',
'dis',
'Cottard',
'sentais',
'Norpois',
'parents',
'simple',
'encore,',
'montrer',
'baron',
'forme',
'soleil',
'vraiment',
'bout',
'm’a',
'voir,',
'«Mais',
'Cette',
'quelle',
'm’en',
'beauté',
'trouvé',
'où,',
'autrefois',
'autres,',
'conversation',
'manière',
'Morel',
'd’autant',
'n’ai',
'voyait',
'petits',
'fois,',
'joie',
'Mais,',
'comment',
'combien',
'Tout',
'font',
'Aussi',
'propre',
'présence',
'l’esprit',
'Gilberte,',
'certaine',
'doit',
'temps,',
'filles',
'sentiment',
'comprendre',
'fallait',
'mer',
'êtes',
'tour',
'fleurs',
'dire,',
'elle-même',
'eussent',
'quel',
'rue',
'l’avais',
'relations',
'voiture',
'Saint-Loup,',
'mari',
'esprit',
'parlait',
'semble',
'maîtresse',
'là,',
'jadis',
'amie',
'justement',
'vérité',
'aussitôt',
'mille',
'Combray',
'demanda',
'tellement',
'«Vous',
'heure',
'donc',
'années',
'bonheur',
'lesquels',
'voyant',
'nature',
'si,',
's’y',
'l’habitude',
'vite',
'compris',
'maître',
'Combray,',
'jour,',
'chacun',
'pauvre',
'propos',
'sentait',
'd’ailleurs,',
'n’avaient',
'Une',
'l’amour',
'celle-ci',
'Paris,',
'phrase',
'tenir',
'charme',
'sommes',
'vient',
'nuit',
'connu',
'retrouver',
'pied',
'fils',
'visite',
'caractère',
'dit:',
'voyais',
'belle',
'J’avais',
'vieille',
'ai',
'«C’est',
'qu’Albertine',
'pût',
'mis',
'ici',
'donne',
'd’où',
'regarder',
'tard,',
'demandé',
'mémoire',
'disait:',
'idée',
'nouvelles',
'semblaient',
'venu',
'peux',
'd’en',
'peuvent',
'derrière',
'dehors',
'eut',
'parfois',
'ans',
'm’eût',
'dernière',
'lesquelles',
'possible',
'Or,',
'non,',
'chemin',
'rien,',
'savez',
'n’aurait',
'eux,',
'jusqu’au',
'mère,',
'parlé',
'Bergotte',
'long',
'Du',
'Ils',
'j’en',
'Françoise,',
'ait',
'salle',
'partir',
'soir,',
'voit',
'l’hôtel',
'tout,',
'Alors',
'qu’au',
'veut',
'entièrement',
'dernier',
'contraire,',
'entrer',
'appris',
'sortir',
'pays',
'aussi,',
'Mon',
'entendre',
'grandes',
'regards',
'simplement',
'absolument',
'quand,',
'Ma',
'quelquefois',
'matin',
'ensuite',
'petites',
'auquel',
'Or',
'ciel',
'd’elle,',
'êtres',
'vais',
'lendemain',
'connaissance',
'disant',
'soirée',
'valeur',
'cours',
'c’est-à-dire',
'«Il',
'j’eusse',
'celui-ci',
'heureux',
'Peut-être',
'vivre',
'cheveux',
'traits',
'noms',
'd’Albertine,',
'part,',
'moments',
'bientôt',
'aimait',
'restait',
'guerre',
'dit-il',
'devoir',
'passait',
'lumière',
'grand’mère,',
'table',
'Puis',
'au-dessus',
'rire',
'nullement',
'mauvais',
'souffrance',
'dire:',
'l’être',
'seconde',
'croyais',
'idées',
'duquel',
'société',
'mauvaise',
'jouer',
'espèce',
'autre,',
'venais',
'dit,',
'amies',
'guère',
'lettres',
'plaisirs',
'D’ailleurs,',
'situation',
'véritable',
'su',
'nom,',
'laissait',
'perdu',
'mois',
'm’étais',
'livre',
'l’autre,',
'davantage',
'fus',
'oncle',
'Andrée',
'mouvement',
'docteur',
'valet',
'haut',
'vrai,',
'hasard',
'père,',
'exemple,',
'qu’avait',
'souvenirs',
'pouvaient',
'pourquoi',
'faire,',
'm’était',
'vous,',
'devenu',
'raisons',
'mais,',
'revenir',
'cependant',
'Cela',
'yeux,',
'recevoir',
'(et',
'voulais',
'Jupien',
'rendait',
'veux',
'duchesse,',
'vis',
'maman',
'sentir',
'obligé',
'Quant',
'premiers',
'rose',
'attention',
'cessé',
'demandait',
'laissé',
'différent',
'alors,',
'pensais',
'doute,',
'bruit',
'l’une',
'Cottard,',
'Ainsi',
'n’ont',
'dîner,',
'marquise',
'reçu',
'paraître',
'causer',
'étions',
'douceur',
'aime',
'ensemble',
'avions',
'pensant',
'prenait',
's’est',
'afin',
'ferait',
'exactement',
'demande',
'l’ai',
'd’y',
'Ces',
'l’a',
'aimé',
'moi-même',
'mains',
'l’homme',
'impression',
'fini',
'travers',
'trouvais',
'chagrin',
'personne,',
'présenter',
'Brichot',
'd’autre',
'moins,',
'jours,',
'capable',
'vos',
'mesure',
'pensait',
'plein',
'musique',
'lui-même,',
'face',
'disais',
'«Ah!',
'moment,',
'chambre,',
'Odette,',
'n’étais',
'voyage',
'nez',
'parmi',
'vois',
'paru',
'maison,',
'cherchait',
'rendu',
'exemple',
'lit',
'difficile',
'signe',
'pourrais',
'n’aurais',
'j’allais',
'douleur',
'paraissait',
'départ',
'Forcheville',
'malade',
'D’ailleurs',
'—Mais',
'mariage',
'précisément',
'nombre',
'revoir',
'cas,',
'quitter',
'haute',
's’ils',
'Même',
'bras',
')',
'd’eux',
'femmes,',
'j’y',
'Berma',
'tendresse',
'dit-elle',
'mettait',
'connaissais',
'avait,',
'arriver',
'écrit',
'dix',
'portrait',
'état',
'Monsieur',
'paraît',
'fait,',
'est-ce',
'Vinteuil',
'faisais',
'minutes',
'venue',
'belles',
'général',
'n’ayant',
'tristesse',
'parle',
'l’eût',
'J’ai',
'retour',
'chapeau',
'impossible',
'parlant',
'silence',
'l’égard',
'auraient',
'rôle',
'chose,',
'pensé',
's’étaient',
'robe',
'aujourd’hui',
'fussent',
'reconnaître',
'marquis',
'vint',
'œuvre',
'déjeuner',
'm’avaient',
'bas',
'sinon',
'plaisir,',
'rentrer',
'Rachel',
'sûr',
'demi',
'connaît',
'Bloch,',
'fille,',
'fenêtre',
'moyen',
'envie',
'arrivé',
'changer',
'couleur',
'parole',
'serais',
'Villeparisis,',
'agréable',
'répondre',
'question',
'auxquels',
'faite',
'ville',
'oublié',
'manger',
'Legrandin',
'sentiments',
'monsieur',
'd’Odette',
'terre',
'curiosité',
'cinq',
'Elstir',
'satisfaction',
'mer,',
'rapport',
'mort,',
'croit',
'l’impression',
'différente',
'connais',
's’écria',
'jalousie',
'maladie',
'promenade',
'etc',
'France',
'beaux',
'manque',
'l’intelligence',
'jusque-là',
'seraient',
'Par',
'pièce',
'sommeil',
'Que',
'différentes',
'droit',
'lire',
'Madame',
'rencontré',
'roi',
'Morel,',
'tantôt',
'famille,',
'faubourg',
'pourtant,',
'génie',
'titre',
'langage',
'époque',
'Cambremer,',
'matière',
'monter',
'joues',
'tort',
'était,',
'l’eau',
'elle-même,',
'expression',
'service',
'quatre',
'faites',
'longue',
'journée',
...]
#un peu de paramètres: min_count= combien de fois un terme doit apparaître pour être mis dans le vocabulaire
model_sg = Word2Vec(sentences=sentences, min_count=1, sg=1, window=10)
model_sg.wv.most_similar('madeleine')
[('tempête', 0.9400717616081238),
('Roussainville,', 0.9392350316047668),
('Montjouvain,', 0.9377919435501099),
('description', 0.9354062676429749),
('plafond', 0.9351763725280762),
('boîte', 0.9307337403297424),
('Boulogne', 0.9298250079154968),
('plénitude', 0.9287278056144714),
('date', 0.9282354712486267),
('brouillard,', 0.92800372838974)]
CBOW#
Le principe est juste inversé: on prend en entrée le contexte pour deviner un mot cible.
Skip-Gram fonctionne bien avec de petits ensembles de données et peut mieux représenter les mots moins fréquents.
CBOW s’entraîne plus rapidement que Skip-Gram, et peut mieux représenter les mots plus fréquents.
model_cbow = Word2Vec(sentences=sentences, min_count=1, sg=0, window=10)
model_cbow.wv.most_similar('madeleine')
[('fuite', 0.9220989346504211),
('fraîcheur', 0.9204322099685669),
('bougie', 0.9201040863990784),
('saison', 0.9167993068695068),
('fenêtre', 0.9135265350341797),
('vision', 0.9111268520355225),
('raideur', 0.9093303680419922),
('digue', 0.9083762764930725),
('lecture', 0.9074811935424805),
('serviette', 0.9036232829093933)]
model.wv.most_similar('temps')
[('temps,', 0.8312168717384338),
('nationalisme', 0.6660643815994263),
('souvenir', 0.6596003770828247),
('désir', 0.6570372581481934),
('sens', 0.6536211967468262),
('plaisir', 0.6476064920425415),
('sentiment', 0.6475840210914612),
('charme', 0.6474167108535767),
('chose', 0.6332330107688904),
('pays', 0.6294322609901428)]
Glove#
Au lieu que prendre en compte le vocabulaire comme input on part de la matrice des co-occurrences des mots. Donc GloVe (Global Vectors) prend en compte les statistiques d’occurences globales et non seulement locales (comme w2v).
Unlike the matrix factorization methods, the shallow window-based methods suffer from the disadvantage that they do not operate directly on the co-occurrence statistics of the corpus. Instead, these models scan context windows across the entire corpus, which fails to take advantage of the vast amount of repetition in the data.
Par exemple, admettons d’avoir la phrase:
La littérature est un art.
W2v sera capable de rendre compte du fait qu’il y a un lien entre “littérature” et “art”. Mais il ne saura pas profitter d’une autre information; combien de fois, dans l’ensemble du corpus, le mot “littérature” et le mot “art” se touvent ensemble?
GloVe ne se requiert pas un réseau de neurones. Les vecteurs sont déterminés sur la base de la probabilité de co-occurence des mots selon la formule: