Topic modeling¶
Classer des textes par thématique.
L’idée est que chaque texte d’un corpus peut appartenir à une ou plusieurs thématiques
LDA¶
La méthode LDA est la plus utilisée. Elle devient presque synonime de topic modeling
LDA est l’acronyme de ‘Latent Dirichlet Allocation’
L’idée derrière LDA est que chaque document puisse être décrit avec une distribution de “sujets” (topics) et que chaque sujet est representé par une distribution de mots.
On commence donc par relier les documents au dictionnaire de tous les mots du corpus:
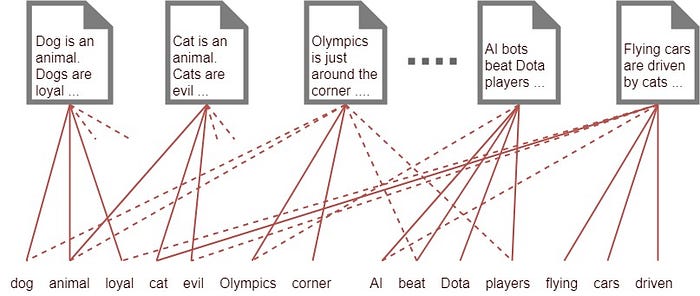
Ensuite il faudra trouver les sujets “cachés” (latent). On le fera en mettant ensemble un certain nombre de mots:
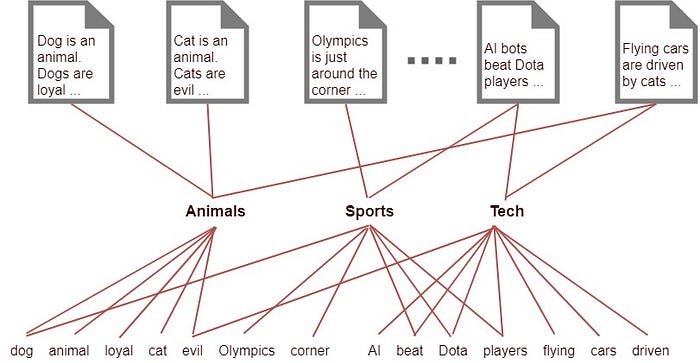
La distribution de Dirichlet est une règle probabilistique qui sert pour calculer la probabilité de distribution dans un espace à n dimensions.
Nombre de sujets¶
Évidemment c’est à nous de déterminer combien de sujet on veut.
Topic modeling sur les épigrammes en anglais de l’AP¶
Nous allons d’abord importer tous les textes en anglais depuis l’api et mettre:
Les textes dans une liste qui s’apelera
english_textsLes titres des textes dans une liste qui s’appelera
text_titles
import json
import requests
entities = requests.get('https://anthologia.ecrituresnumeriques.ca/api/v1/entities/').json()
english_texts=[]
text_titles=[]
for entity in entities:
for version in entity['versions']:
if version['id_language'] is 3:
if 'Iliad' not in entity['title']: # l'iliade fait bcp de bruit!
text = version['text_translated']
english_texts.append(text)
text_titles.append(entity['title'])
D’abord on doit télécharger et décomprimer http://mallet.cs.umass.edu/download.php. C’est une librairie pour faire du LDA. Cf. ici https://melaniewalsh.github.io/Intro-Cultural-Analytics/Text-Analysis/Topic-Modeling-Overview.html
Puis on installe un wrapper
import little_mallet_wrapper # mallet
import seaborn # dataviz library
# on déclare le chemin de mallet
path_to_mallet = '/home/marcello/Downloads/mallet-2.0.8/bin/mallet'
Maintenant nous allons utiliser une fonction de mallet: little_mallet_wrapper.process_string() et l’appliquer à tous les textes anglais. C’est une fonction qui va normaliser les textes:
mettre en minuscule
enlever les stopwords
enlever la punctuation
enlever les chifres
On va mettre les textes normalisés dans la liste training_data
training_data = []
stfile='/home/marcello/Downloads/mallet-2.0.8/stoplists/en.txt'
with open(stfile, 'r') as file:
stopwords=file.read().split('\n')
#stopwords=['one', 'would', 'say', 'give', 'came', 'much', 'thou', 'thy', 'thee', 'shall', 'even']
for text in english_texts:
#processed_text = little_mallet_wrapper.process_string(text, numbers='remove', remove_stop_words=True)
processed_text = little_mallet_wrapper.process_string(text, numbers='remove', stop_words=stopwords)
training_data.append(processed_text)
La fonction little_mallet_wrapper.print_dataset_stats() donne des statiststiques sur les données:
little_mallet_wrapper.print_dataset_stats(training_data)
Number of Documents: 1283
Mean Number of Words per Document: 20.9
Vocabulary Size: 7525
num_topics = 5 # on décide combien de topics nous voulons identifier
training_data = training_data # les données à processer (on les a déjà mises dans la liste training_data)
from pathlib import Path # librairie pour se simplifier la vie en manipulant les chemins
#On va mettre les outputs dans le dossier topics. C'est ici que les données pour l'entrainement seront stockées
output_directory_path = 'topics'
#No need to change anything below here
Path(f"{output_directory_path}").mkdir(parents=True, exist_ok=True)
path_to_training_data = f"{output_directory_path}/training.txt"
path_to_formatted_training_data = f"{output_directory_path}/mallet.training"
path_to_model = f"{output_directory_path}/mallet.model.{str(num_topics)}"
path_to_topic_keys = f"{output_directory_path}/mallet.topic_keys.{str(num_topics)}"
path_to_topic_distributions = f"{output_directory_path}/mallet.topic_distributions.{str(num_topics)}"
On importe les données¶
Avec la fonction little_mallet_wrapper.import_data()
little_mallet_wrapper.import_data(path_to_mallet,
path_to_training_data,
path_to_formatted_training_data,
training_data)
Importing data...
Complete
Entrainement¶
Avec la fonction little_mallet_wrapper.train_topic_model()
little_mallet_wrapper.train_topic_model(path_to_mallet,
path_to_formatted_training_data,
path_to_model,
path_to_topic_keys,
path_to_topic_distributions,
num_topics)
Training topic model...
Complete
Visualiser!¶
La fonction little_mallet_wrapper.load_topic_keys() va lire et analyser l’output de l’entrainement.
topics = little_mallet_wrapper.load_topic_keys(path_to_topic_keys)
for topic_number, topic in enumerate(topics):
print(f"✨Topic {topic_number}✨\n\n{topic}\n")
✨Topic 0✨
['tomb', 'sea', 'man', 'land', 'earth', 'lie', 'son', 'end', 'ship', 'stranger', 'evil', 'buried', 'dead', 'bones', 'rest', 'monument', 'stone', 'slew', 'perished', 'body']
✨Topic 1✨
['man', 'good', 'long', 'time', 'heart', 'woman', 'men', 'day', 'poor', 'gods', 'things', 'hail', 'back', 'don', 'fell', 'friend', 'sleep', 'grey', 'hold', 'make']
✨Topic 2✨
['love', 'sweet', 'wine', 'eyes', 'muses', 'night', 'zeus', 'longer', 'fire', 'hair', 'cypris', 'graces', 'bacchus', 'drink', 'loves', 'dear', 'flowers', 'song', 'cup', 'sing']
✨Topic 3✨
['god', 'son', 'men', 'made', 'light', 'soul', 'great', 'holy', 'art', 'death', 'christ', 'wisdom', 'city', 'hath', 'beauty', 'lies', 'heaven', 'house', 'gave', 'country']
✨Topic 4✨
['hades', 'life', 'dead', 'death', 'mother', 'father', 'died', 'tomb', 'left', 'age', 'child', 'earth', 'hand', 'children', 'fate', 'tears', 'house', 'alas', 'hast', 'wife']
Distibution des topics¶
la fonction little_mallet_wrapper.load_topic_distributions() crée une liste avec la distribution des topics (en probabilité) par text.
topic_distributions = little_mallet_wrapper.load_topic_distributions(path_to_topic_distributions)
topic_distributions[1] #distribution pour le texte 2
[0.00784313725490196,
0.043137254901960784,
0.7411764705882353,
0.09803921568627451,
0.10980392156862745]
On peut coupler les textes avec leurs titres pour avoir une meilleure idée:
text_to_check = "Greek Anthology 7.22"
text_number = text_titles.index(text_to_check)
print(f"Topic Distributions for {text_titles[text_number]}\n")
for topic_number, (topic, topic_distribution) in enumerate(zip(topics, topic_distributions[text_number])):
print(f"✨Topic {topic_number} {topic[:6]} ✨\nProbability: {round(topic_distribution, 3)}\n")
Topic Distributions for Greek Anthology 7.22
✨Topic 0 ['tomb', 'sea', 'man', 'land', 'earth', 'lie'] ✨
Probability: 0.029
✨Topic 1 ['man', 'good', 'long', 'time', 'heart', 'woman'] ✨
Probability: 0.059
✨Topic 2 ['love', 'sweet', 'wine', 'eyes', 'muses', 'night'] ✨
Probability: 0.676
✨Topic 3 ['god', 'son', 'men', 'made', 'light', 'soul'] ✨
Probability: 0.059
✨Topic 4 ['hades', 'life', 'dead', 'death', 'mother', 'father'] ✨
Probability: 0.176
import random
target_labels = random.sample(text_titles, 100)
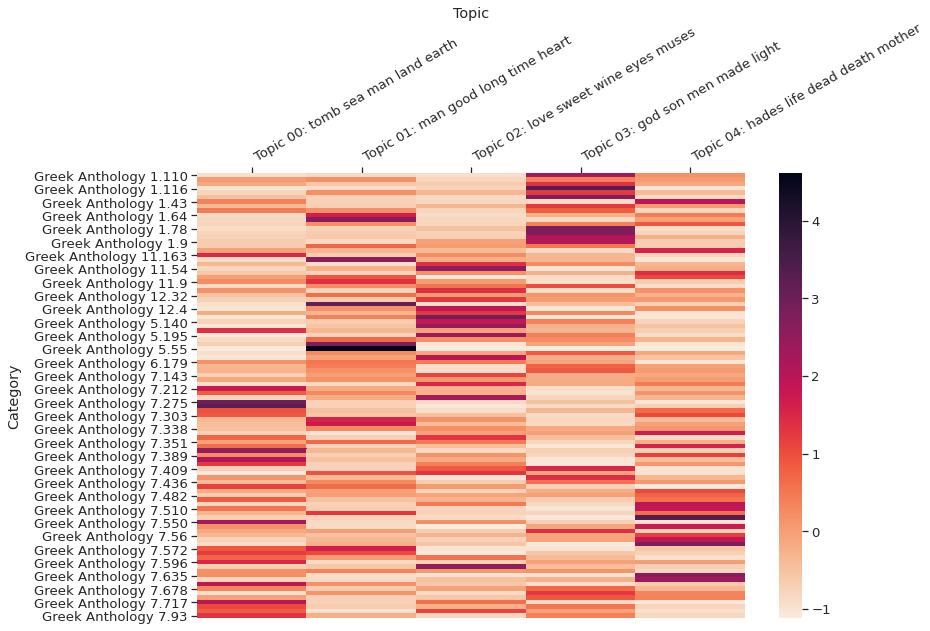
little_mallet_wrapper.plot_categories_by_topics_heatmap(text_titles,
topic_distributions,
topics,
output_directory_path + '/categories_by_topics.pdf',
target_labels=target_labels,
dim= (13, 9)
)
training_data_text_titles = dict(zip(training_data, text_titles))
training_data_original_text = dict(zip(training_data, english_texts))
def display_top_titles_per_topic(topic_number=0, number_of_documents=5):
print(f"✨Topic {topic_number}✨\n\n{topics[topic_number]}\n")
for probability, document in little_mallet_wrapper.get_top_docs(training_data, topic_distributions, topic_number, n=number_of_documents):
print(round(probability, 4), training_data_text_titles[document] + "\n")
return
display_top_titles_per_topic(topic_number=1, number_of_documents=50)
✨Topic 1✨
['man', 'good', 'long', 'time', 'heart', 'woman', 'men', 'day', 'poor', 'gods', 'things', 'hail', 'back', 'don', 'fell', 'friend', 'sleep', 'grey', 'hold', 'make']
0.92 Greek Anthology 5.55
0.92 Greek Anthology 5.55
0.92 Greek Anthology 5.55
0.84 Greek Anthology 11.17
0.8298 Greek Anthology 5.35
0.7895 Greek Anthology 12.3
0.7586 Greek Anthology 11.103
0.7576 Greek Anthology 5.105
0.75 Greek Anthology 5.104
0.7097 Greek Anthology 11.73
0.7037 Greek Anthology 5.182
0.6897 Greek Anthology 5.208
0.6818 Greek Anthology 12.35
0.6786 Greek Anthology 5.23
0.6667 Greek Anthology 7.121
0.6364 Greek Anthology 5.36
0.6364 Greek Anthology 11.82
0.6296 Greek Anthology 11.114
0.6154 Greek Anthology 7.206
0.6 Greek Anthology 5.46
0.6 Greek Anthology 1.73
0.6 Greek Anthology 5.184
0.6 Greek Anthology 7.126
0.5938 Greek Anthology 11.29
0.5932 Greek Anthology 11.74
0.5909 Greek Anthology 5.103
0.5833 Greek Anthology 12.6
0.5833 Greek Anthology 1.63
0.5833 Greek Anthology 11.21
0.5814 Greek Anthology 5.129
0.5556 Greek Anthology 7.107
0.5484 Greek Anthology 5.49
0.5417 Greek Anthology 5.111
0.5417 Greek Anthology 11.65
0.5385 Greek Anthology 5.25
0.5333 Greek Anthology 5.186
0.5312 Greek Anthology 12.27
0.5312 Greek Anthology 11.11
0.5312 Greek Anthology 11.171
0.5294 Greek Anthology 7.102
0.5263 Greek Anthology 7.521
0.5238 Greek Anthology 11.311
0.5185 Greek Anthology 5.19
0.5185 Greek Anthology 5.130
0.5185 Greek Anthology 11.35
0.5172 Greek Anthology 5.127
0.5 Greek Anthology 5.99
0.5 Greek Anthology 7.719
0.5 Greek Anthology 5.29
0.5 Greek Anthology 11.89